推荐系统召回算法:基于用户的协同过滤(UserCF)
1. 算法原理
如果用户 A 和用户 B 的兴趣相似,而其中一位用户对某个物品感兴趣,那么另一位用户也很有可能对这个物品感兴趣。这就是基于用户的协同过滤(UserCF)算法的基本思想。
那么,推荐系统如何知道用户 A 和用户 B 的兴趣相似呢?例如:
- 思路 1:如果用户 A 喜欢的物品和用户 B 喜欢的物品有很多重合(或者说点击、点赞、收藏、转发等行为有很多重合),那么用户 A 和用户 B 的兴趣相似。
- 思路 2:如果用户 A 关注的用户和用户 B 关注的用户有很多重合,那么用户 A 和用户 B 的兴趣相似。
2. 算法实现
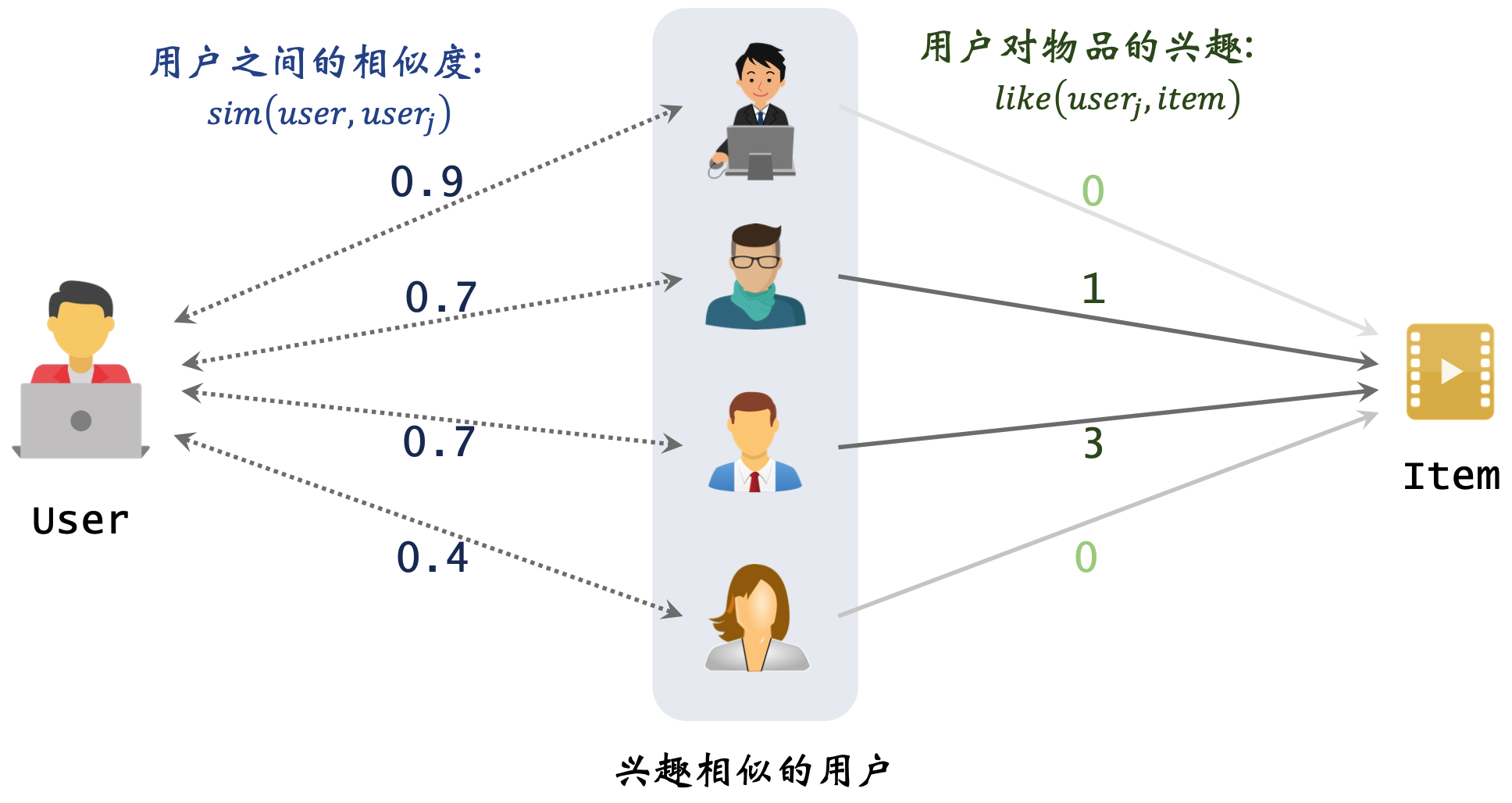
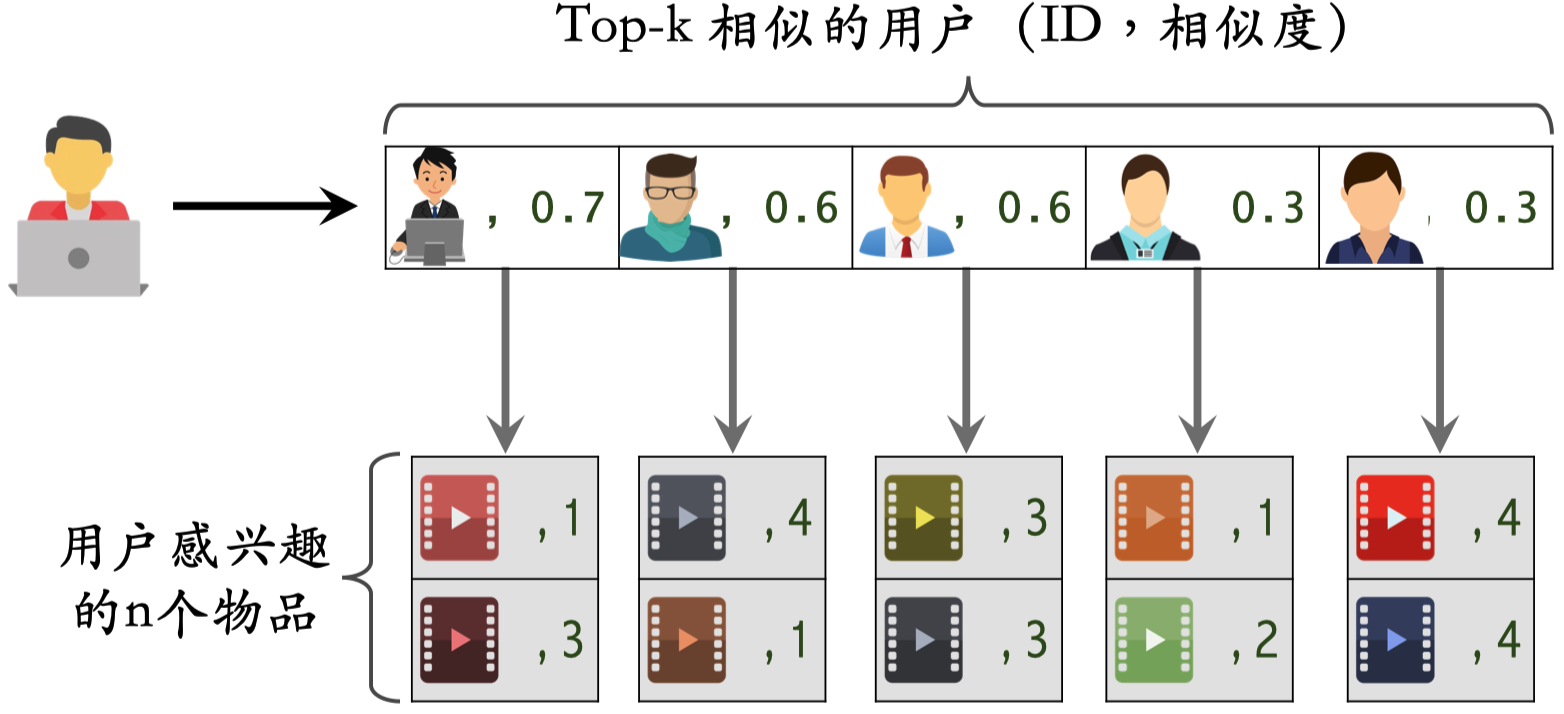
如上图所示,我们可以通过下面的步骤决定为用户推荐哪些物品:
- 找到与用户兴趣相似的用户集合(假设我们可以得到任意两个用户之间的相似度);
- 计算相似用户对候选物品 Item 的喜好程度,这个可以通过用户历史行为日志得到(例如:点击记 1 分,点赞记 2 分,收藏记 3 分);
- 结合两者预估用户对候选物品的喜好程度,然后根据预估的喜好程度对候选物品进行排序,将排序靠前的物品推荐给用户。
用户对每个候选物品的喜好程度,可以通过下面的公式计算:
其中,
根据上面的公式,我们可以预估上图中用户对候选物品 item 的喜好程度:
3. 用户相似度的计算
基于用户的协同过滤算法在计算用户相似度时的基本思想是:如果两个用户喜欢的物品有很多重合,那么这两个用户就很相似。
下面两张图片分别展示了两个用户感兴趣的物品的重合度,其中前者是两个用户不相似的情况,后者是两个用户相似的情况。
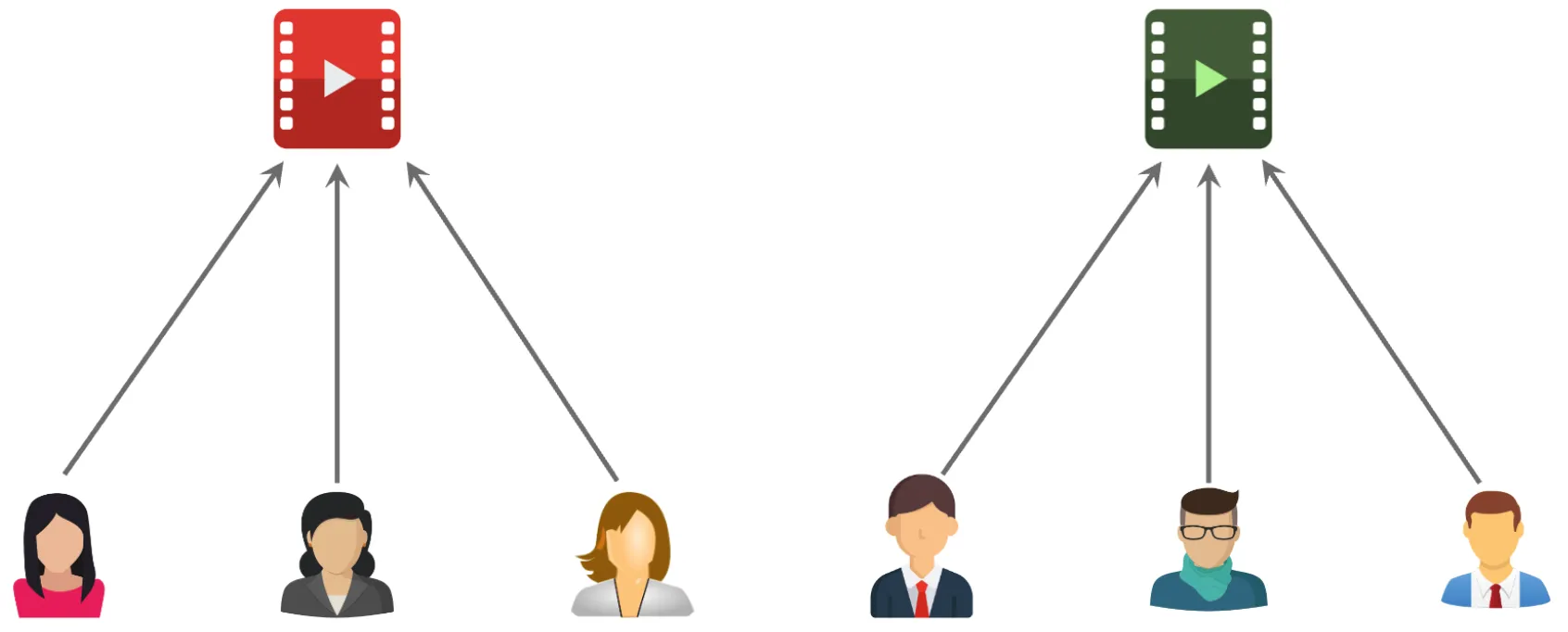
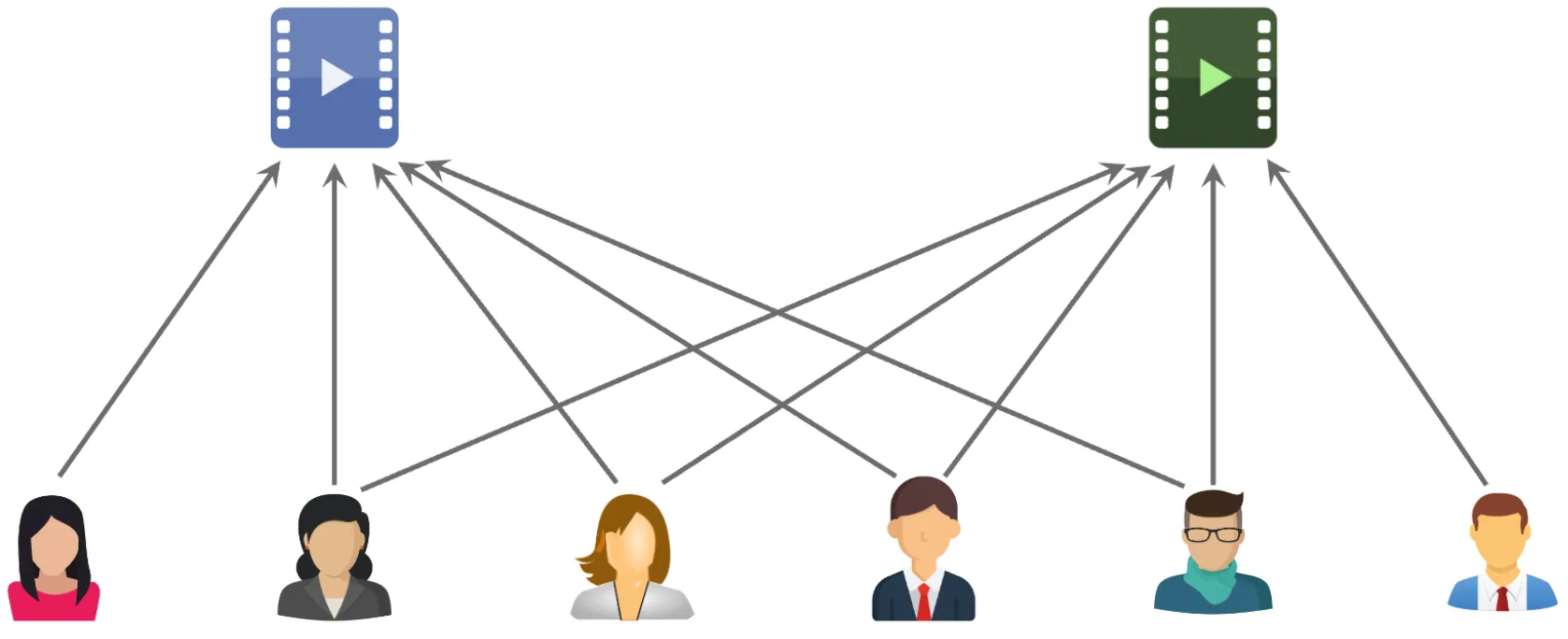
接下来介绍如何量化用户的相似度。假设用户
其中,
这种计算用户相似度的方法存在一个问题:没有考虑热门物品对相似度的影响。我们可以通过降低热门物品的权重来解决这个问题,例如在计算用户相似度时,可以将用户喜欢的物品的权重设置为物品的热度的倒数:
其中,
4. 算法在实际应用中的完整流程
UserCF 算法在实际召回应用中,我们需要事先建立两个索引表:
- 用户-用户表:记录每个用户最相似的
- 用户-物品表:记录每个用户最近点击交互过的物品列表,以及每个物品的喜好程度,根据时间倒序排列,取前
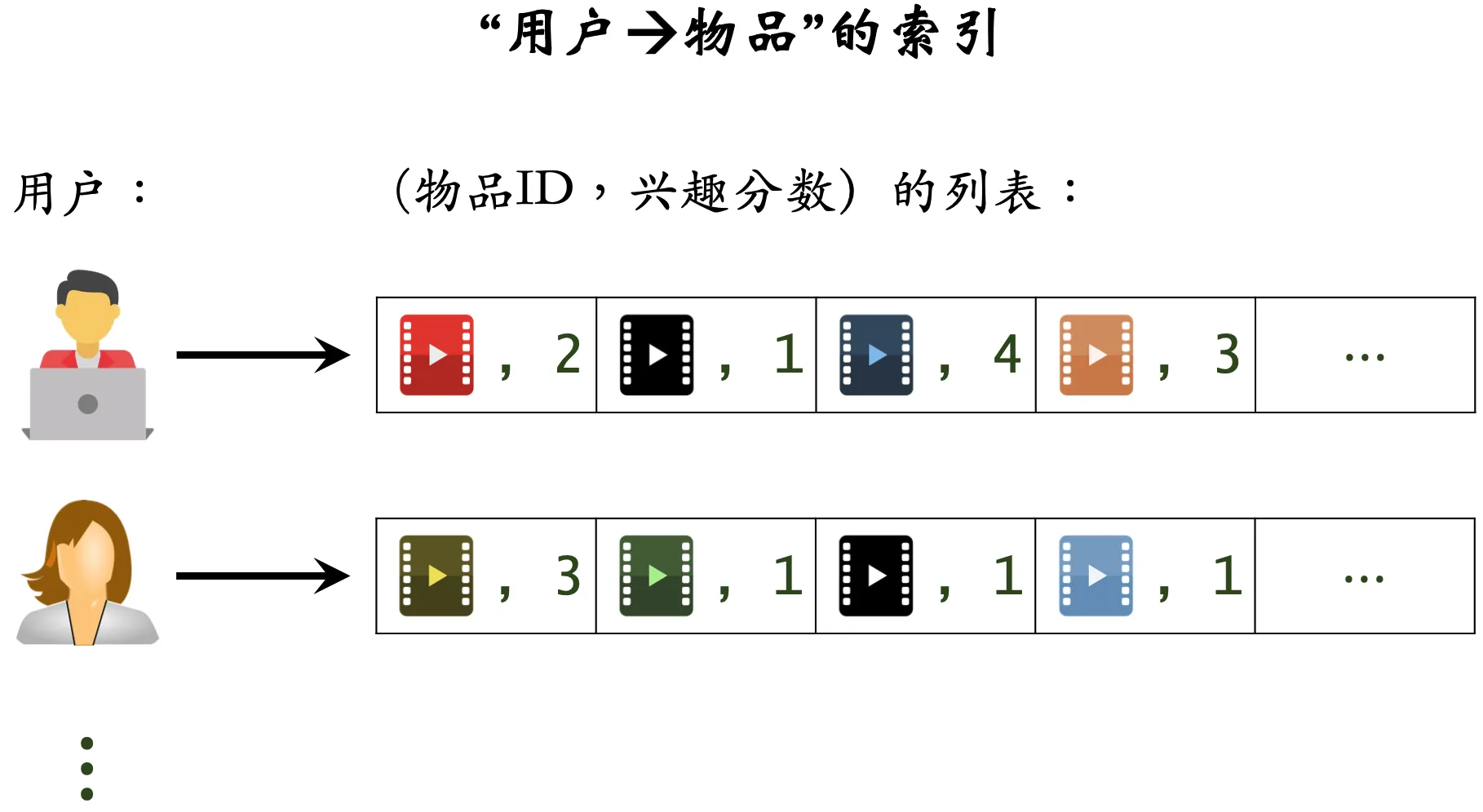

在线上实际应用中,我们可以通过“用户-用户表”来获得与用户最相似的 k 个用户(top-k-users),然后通过“用户-物品表”来获得这些相似用户的近期感兴趣的物品列表(last-n-items),然后再根据公式预估用户对取回的这
5. 总结
-
User 算法的基本思想是:如果用户 A 和用户 B 的兴趣相似,而其中一位用户对某个物品感兴趣,那么另一位用户也很有可能对这个物品感兴趣。
-
计算用户相似度:
- 如果两个用户喜欢的物品有很多重合,那么这两个用户就很相似
-
计算用户相似度时,可以对热门物品降权,例如:
-
线上做召回:
- 维护两个索引表:用户-用户表(相似度最高的
- 利用两个索引表,每次返回分数最高的
-
预估用户对物品的喜好分数:
- 返回用户喜欢的物品列表(例如 Top100),作为召回结果。
- 维护两个索引表:用户-用户表(相似度最高的
6. 参考资料
- https://github.com/wangshusen/RecommenderSystem(本文图片均来自此repo)
- 王哲《深度学习推荐系统》
Enjoy Reading This Article?
Here are some more articles you might like to read next: